
City University of New York (CUNY) City University of New York (CUNY)
CUNY Academic Works CUNY Academic Works
Open Educational Resources Queensborough Community College
2020
Clear-Sighted Statistics: Appendix 3: Common Statistical Symbols Clear-Sighted Statistics: Appendix 3: Common Statistical Symbols
and Formulas and Formulas
Edward Volchok
CUNY Queensborough Community College
How does access to this work bene;t you? Let us know!
More information about this work at: https://academicworks.cuny.edu/qb_oers/143
Discover additional works at: https://academicworks.cuny.edu
This work is made publicly available by the City University of New York (CUNY).
Contact: AcademicWorks@cuny.edu

Clear-Sighted Statistics: An OER Textbook
Appendix 3: Common Statistical Symbols and Formulas
I. Introduction
This appendix lists common statistical symbols and formulas used in Clear-Signed Statistics.
The terms and formulas presented here are explained in detail in the appropriate modules
of Clear-Sighted Statistics.
II. Common Statistical Symbols and Formula
A. Module 4: Picturing Data with Tables and Charts
Symbol/Formula
Description
N
Number of observations, or items, in a population
n
Number of observations, or items, in a sample
k
Number of categories, classes, buckets, or bins in a Frequency
Distribution
2 to the k formula
2
k
> n. Formula used to determine the number of categories,
classes, buckets, or bins in a Frequency Distribution
H
The highest value in a distribution
L
The smallest value in a distribution
Class Interval or
Width, i
f
Frequency or the number of observations
RF or %
Relative frequency or the proportion of the total number of
observations
Class Midpoint
Table 1: Module 4 Symbols and Formulas
B. Module 5: Statistical Measures
Symbol/Formula
Description
X
X stands for the random variable
Σ
Σ (capital Greek letter Sigma). It means the operation of
summation or addition
X̅ (The Sample
Mean, X-Bar)
, where X are the random variables

μ (The Population
Mean, mu)
where X are the random variables
X̅
W
(Weighted
Mean)
where X are the random variables and w are the
weights
Median
M or Med or “x-tilde”
Mode
Mo
Range
Range = H (Highest Value) – L (lowest Value)
M, Med, or
Median
Mean Deviation
(MD) or Mean
Absolute Deviation
(MAD)
where “| |” means the absolute value, the
distance of a positive or negative number from zero, or the
value of a number regardless of its negative or positive sign.
σ
2
(Population
Variance, sigma-
squared)
s
2
(Sample
Variance, s-
squared)
σ (Population
Standard
Deviation, sigma)
s (Sample Standard
Deviation, s)
Sample Mean,
Grouped Data
Sample Standard
Deviation, Grouped
Data
D
Stands for Decile. Deciles divide a distribution into ten
groups of equal frequency
Location of a Decile
P
Stands for Percentile. P75 or P
75
means the 75
th
percentile.
Percentiles divide a distribution into a hundred groups of
equal frequency.
Location of a
Percentile

Q
Stands for Quartile: Q
1
(1
st
Quartile), Q
2
(2
nd
Quartile), Q
3
(3
rd
Quartile) and Q
4
(4
th
Quartile). Quartiles divide a distribution
into four groups of equal frequency.
Location of a
Quartile
Interquartile
Range (IQR)
Lower Outlier
(Extreme Lower
Outlier)
Upper Outlier
(Extreme Upper
Outlier)
Coefficient of
Variation as a
percentage
Coefficient of
Variation as an
index
Skewness or SK
Pearson’s
Coefficient of
Skewness
Trimean
Table 2: Module 5 Descriptive Statistics Measures
C. Module 6: Index Numbers
Symbol/Formula
Description
Simple Index
Number
Simple Price Index
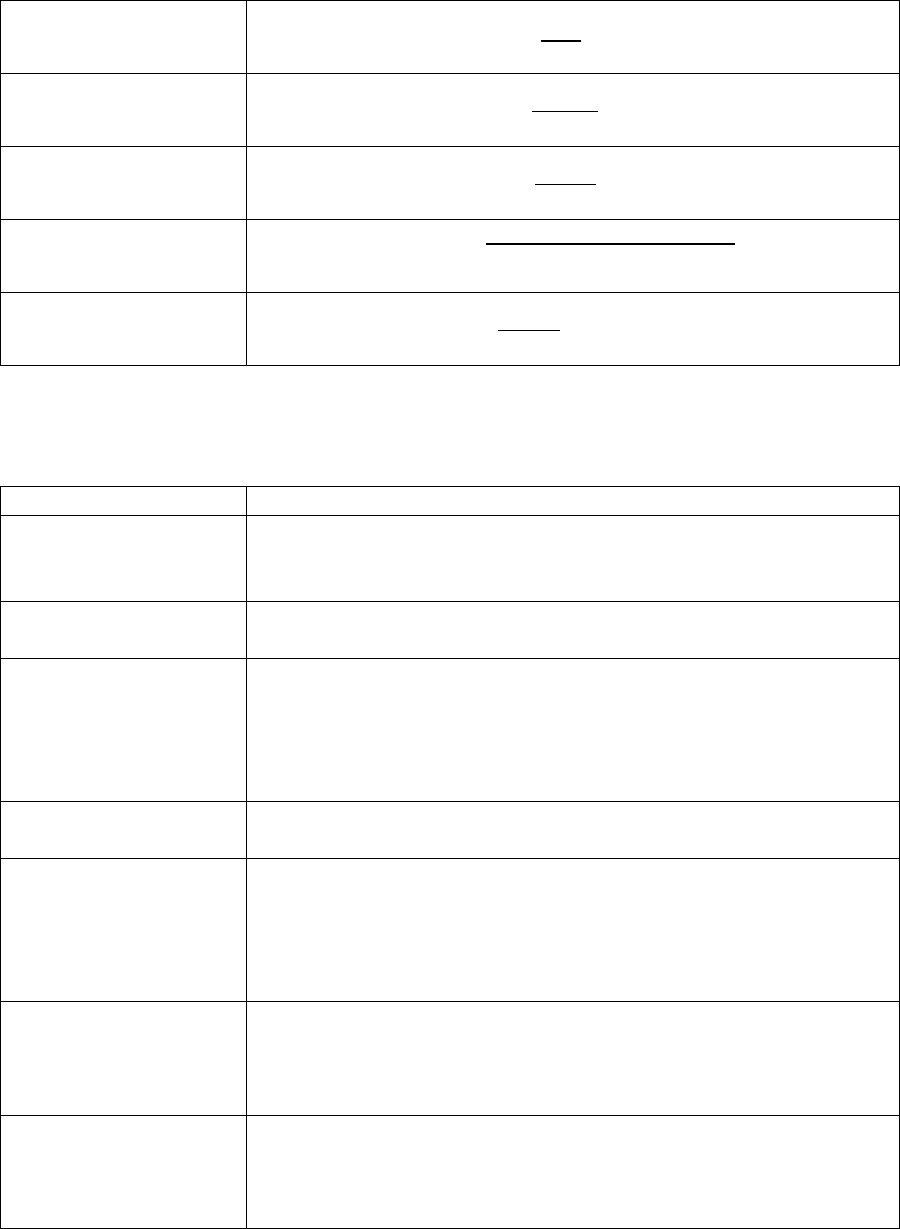
Simple Aggregate
Price Index
Laspeyres Index
Paasche Index
Fisher’s Ideal Index
Value Index
Table 3: Module 6: Index Numbers
D. Module 7: Basic Concepts of Probability
Symbol/Formula
Description
P(A)
The probability of event “A”
P(~A)
The probability of the event not A. This is called the
complement of event A. It is sometimes written as P(A
C
) or
P(not A).
P(A|B)
The probability of event A given than event B has happened.
This is called conditional probability.
Special Rule of
Addition (for
mutually exclusive
events)
or
Note: is pronounced “union” and is the equivalent to the
word “or”
Complement Rule
(Subtraction Rule)
General Rule of
Addition (for non-
mutually exclusive
events
or
Note: is pronounced as “intersection.” It is the equivalent
to the word “and.”
Special Rule of
Multiplication (for
independent events
or
General Rule of
Multiplication (for
dependent events
or

Bayes Theorem
Multiplication
Formula
(o)
Factorial Number
n! (The factorial of a non-negative integer n, denoted by n!,
is the product of all positive integers less than or equal to n:
4! = 1 x 2 x 3 x 4 = 24.)
Permutations
n
P
r
n
P
r
is pronounced “the permution of r things
selected from n things.”
Note: With permutations, the order of selection matters.
Combinations
n
C
r
n
C
r
is pronounced “the combination of r things
selected from n things.”
Note: With combinations, the order of selection matters.
Table 4: Module 7: Basic Concepts of Probability
E. Module 8: Discrete Probability Distributions
1) Mean of a Probability Distribution, μ
μ = Σ[xP(x)], found by multiplying each value by its probability and then
adding the product of each value times its probability.
2) Variance of a Probability Distribution, σ
2
σ
2
= Σ[(X – μ)
2
P(x)], found by, 1) Subtract the mean from each random value, x,
2) Square (x – μ), 3) Multiply each square difference by its probability, and 4)
Sum the resulting values to arrive at σ
2
.
3) Standard Deviation of a Probability Distribution, σ
σ = σ
2
, the standard deviation is the positive square root of variance.
4) Binomial Probability Formula
P(x) = nCxπ
x
(1 – π)
n – x
, where C denotes combinations, n is the number of
trials, x is the random number of successful trials, π is the probability of a
success for each trial. Note: π, or pi, is not the mathematical constant of
3.14159 that you used in your geometry class to find the circumference of a
circle.

5) Mean of a Binomial Distribution
μ = nπ
6) Variance of a Binomial Distribution
μ = nπ(1 - π)
7) Hypergeometric Distribution
P(x) =
(
s
C
x
)(
n-s
C
n-x
)
N
C
n
Where N is the size of the population; S is the number of successes in the
population; x is the number of successes (It could be 0, 1, 2, 3, 4, …); n is the
size of the sample (number of trials); and C is the combinations.
8) Poisson Distribution
P(x) =
m
x
e
-m
x!
Where μ is the mean number of successes in a particular interval; e is the
constant or base of the Naperian logarithmic system, 2.71828’ x is the number
of successes; and P(x) is the probability of a specified value of x.
9) Mean of a Poisson Distribution
μ = nπ
F. Module 9: Continuous Probability Distributions
Symbol/Formula
Description
Standard Normal
Value
Standard Error for
the Mean, sigma
sub x-bar or SEM
z-value, μ and σ
known
Solving for X
X = μ + zσ
Note: z can be either a positive or negative number.
Table 5: Module 9: Continuous Probability Distribution
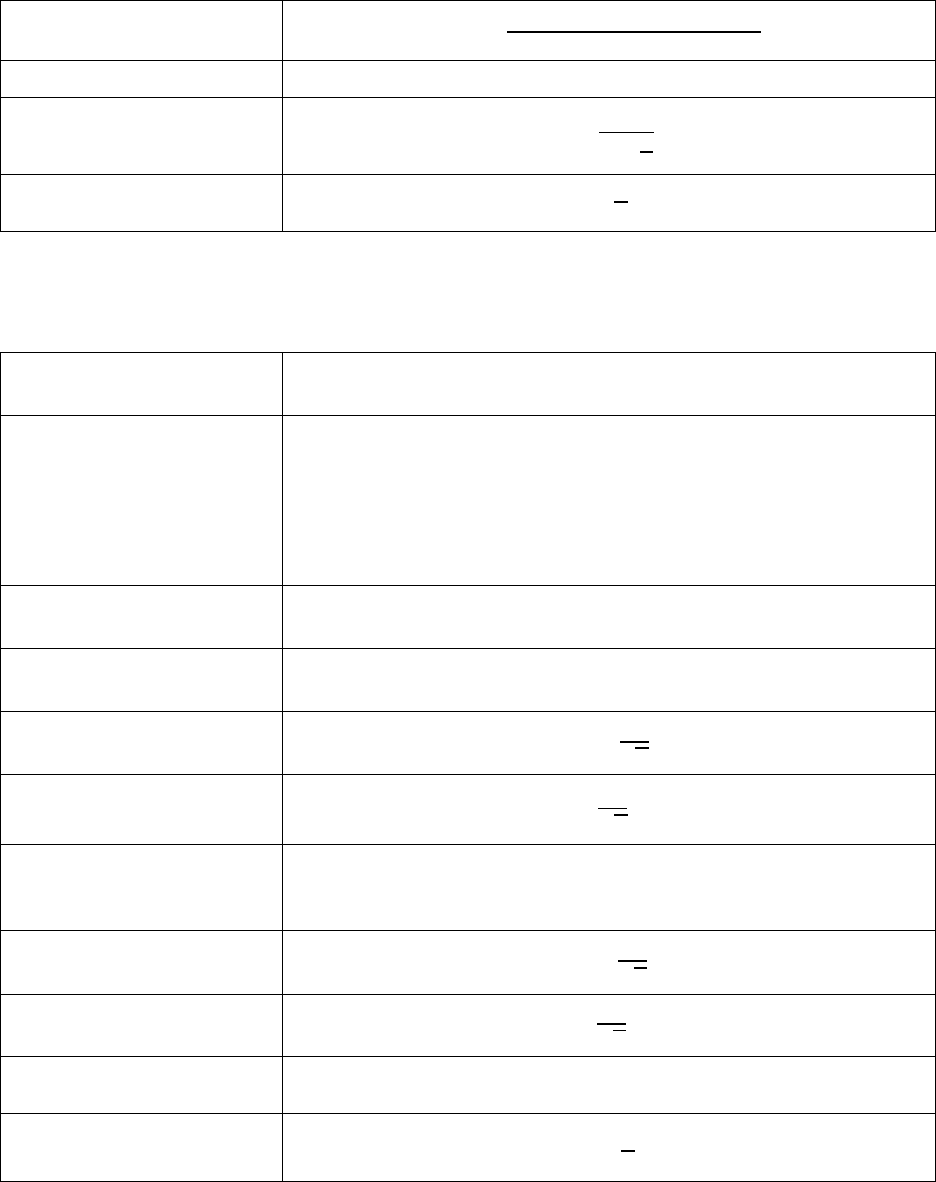
G. Module 10: Sampling and Sampling Errors
Symbol/Formula
Description
Mean of the Sample
Means (mu sub x-bar)
Sampling Error
X̅ - μ = 0 or X̅ ≠ μ
z-value for sample
Standard Error of the
Mean, SEM, or
Table 6: Module 10: Sampling and Sampling Errors
H. Module 11: Confidence Intervals
Symbol/Formula
Description
c
The selected confidence level; usually 95%, but in some
cases 99% or 90%.
Critical Value
The value a test statistic must exceed to be out of the
confidence interval or the value a test statistics must exceed
to reject the Null Hypothesis. A test statistic is a value
derived from a sample for the purposes of hypothesis testing
and confidence intervals. Do not report the Critical Value as
CV. CV is the Coefficient of Variance.
z
c
The critical value for a confidence level using z values.
t
c
The critical value for a confidence level using t values.
Confidence Interval for
Means using z
Margin of Error for the
Mean using z
d.f., df, or ν (the lower-
case or small Greek
letter nu)
Note: The formula for degrees of freedom depends on the
type of distribution used.
Confidence Interval for
Means using t
Margin of Error for the
Mean using t
Sample Proportion, p
Sample Proportion = p (a lower-case p). A commonly used
symbol for the sample proportion is p-hat, .
Sample Proportion
formula
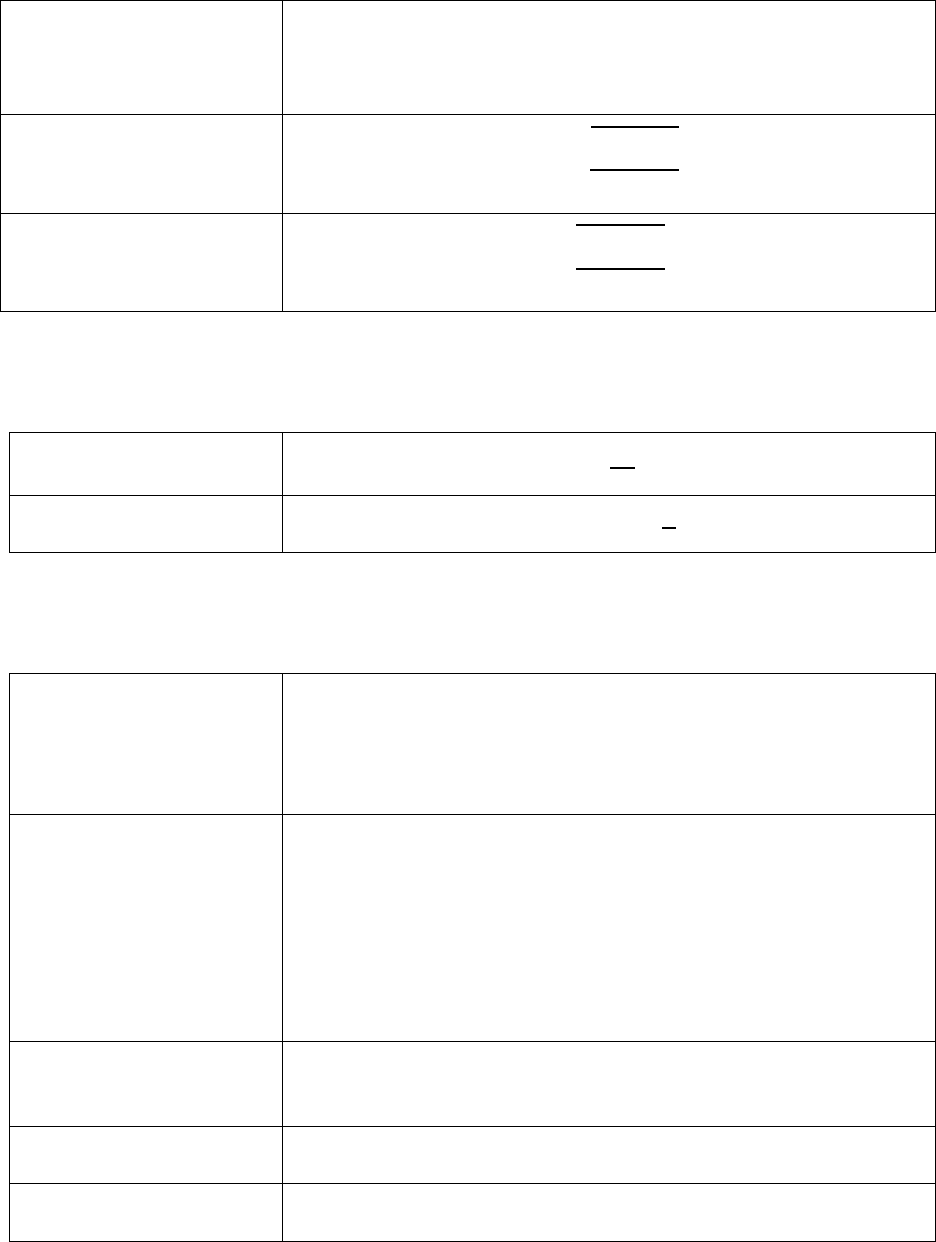
Population Proportion
Population Proportion = π. Some use a capital P to symbolize
the Population Proportions. In Clear-Sighted Statistics
population parameters are always symbolized with Greek
letters.
Standard Error for the
Proportion (σ
p
, SEP or
SE
P
)
Confidence Interval for
Proportions
Table 7: Module 11: Confidence Intervals
I. Module 12: Estimating Sample Size
Symbol/Formula
Description
Estimating Sample
Size for the Mean
Estimating Sample
size for the Proportion
Table 8: Module 12: Estimating Sample Size
J. Module 13: Introduction to Null Hypothesis Significance Testing
Symbol/Formula
Description
H
0
The Null Hypothesis. H
0
is pronounced “H sub-zero” or “H
sub naught.” H
0
is a hypothesis about a population
parameter. The Null Hypothesis states that there is no effect.
Any difference between the parameter and the statistic is
due to sampling error.
H
1
or H
A
The Alternate Hypothesis, sometimes called the Research
Hypothesis. The Alternate Hypothesis is pronounced “H sub-
one” when the H
1
symbol is used or “H sub-A” when the H
A
symbol is used. Like the Null Hypothesis, the Alternate
Hypothesis is a statement about a population parameter. The
Alternate hypothesis states that there is an effect, which
means the difference between the parameter and statistic is
too big to have occurred by chance.
α (alpha)
The level of significance. The level of significance is selected
by the researcher or analyst. Alpha is also the likelihood of a
Type I Error.
P(α)
The probability of a Type I Error, or rejecting a Null
Hypothesis when we should fail to reject it.
β (beta)
A Type II Error or failing to reject a Null Hypothesis that
should be rejected.

p-value
The p-value represents the likelihood of obtaining a test
statistic as extreme or more extreme than the one obtained.
If the p-value is greater than the level of significance, fail to
reject the Null Hypothesis. When the p-value is equal to or
less than the level of significance, reject the Null Hypothesis.
Table 9: Module 13: Introduction to Null Hypothesis Significance Testing
K. Module 14: One-Sample Tests of Hypothesis (Normal and Student t Distributions)
Symbol/Formula
Description
One-Sample test for
the Mean when σ is
known
One-Sample test for
the Mean when σ is
unknown
One-Sample test for
the Proportion
Probability of a Type
II Error P(β)
Power of a Test
Cohen’s d Effect Size
delta, δ, for the mean
delta, δ, for the
proportion
Table 10: Module 14: One-Sample Tests of Hypothesis
L. Module 15: Two-Sample Tests of Hypothesis (Normal and Student t Distributions)
Symbol/Formula
Description
Variance of the
Distribution of
differences in Means
Two-sample z-test of
Means

Pooled Standard
Deviations
Cohen’s d
Cohen’s h (ES for
population)
Pooled Proportion
Two-sample z-test of
Proportions
Pooled Variance t-test
for Means (equal
Variance)
Pooled Variance
F-Test for comparing
two sample variances
Two-Sample t-test for
Means (Unequal
Variance)
df for Unequal
Variance t-test
d
The difference between paired or dependent samples.
The mean of the difference between paired or dependent
samples.
Paired t-test for
dependent samples
Table 11: Module 15: Two-Sample Tests of Hypothesis
M. Module 16: ANOVA
Symbol/Formula
Description

Sum of Square, total
Sum of Square, error
Sum of Square,
treatment
Eta-squared, η
2
, Effect
Size
Confidence Interval
for difference in
Treatment Means
Table 12: Module 16 ANOVA
N. Module 17: Chi-Square Tests
Symbol/Formula
Description
Chi-Square (χ
2
)
Goodness of Fit Test
Where f
o
stands for the Observed Frequencies for each
category and f
e
stands for the Expected Frequencies for each
category.
Chi-Square Expected
Frequency for a
Contingency Table
Cohen’s w Effect Size
Degrees of Freedom
for a Goodness of Fit
df = k – 1
Degrees of Freedom
for a contingency
table
Degrees of Freedom
for a Goodness of Fit
test for Normality
df = k – 3
(The two extra degrees of freedom are needed because we
use the sample mean and sample standard deviation.)
Table 13: Module 17 Chi-Square Tests
O. Module 18: Linear Correlation and Regression
Symbol/Formula
Description
Coefficient of
Correlation or r

Coefficient of
Determination or r
2
r
2
or
Test for the
significance of r
ρ, or the lower-case
Greek letter rho
Linear Regression
Equation (y-hat)
Slope of the
Regression Line
Intercept of the
Regression Line
Test for Zero Slope
Standard Error of
the Estimate
Confidence Interval
Prediction Interval
Table 14: Module 18 Linear Correlation and Regression
P. Microsoft Excel Statistical Functions
Analysis ToolPak
Anova: Single Factor
Correlation
Descriptive Statistics
F-Test Two-Sample for Variance
Histogram
Moving Average
Rank and Percentile
Regression
Sampling
t-Test: Paired Two Samples for Means
t-Test: Two-Sample Assuming Equal Variances
t-Test: Two-Sample Assuming Unequal Variances
z-Test: Two Sample for Means
Math Functions
ABS, POWER, ROUND, ROUNDDOWN, ROUNDUP, SQRT, SUM, SUMIF, SUMIFS,
SUMPRODUCT, SUMSQ
Frequency Distribution Functions:
FREQUENCY
Descriptive Statistics Functions:
AVEDEV, AVERAGE, AVERAGEA, AVERAGEIF, AVERAGEIFS, COUNT, COUNTA,
COUNTBLANK, CCOUNTIF, COUNTIFS, FREQUENCY, GEOMEAN, HARMEAN, KURT, LARGE,
MAX, MAXA, MAXIFS, MEDIAN, MIN, MINA, MINIFSM MODE.MULT, MODE.SNGL,
PERCENTILE.EXC, PERCENTILE.INC, PRECENTRANK.EXC, PERCENTRANK.INC,
QUARTILE.EXC, QUARTILE.INC, RANK.AVG, RANK.EQ, SKEW, SKEW.P, SMALL, STDEV.P,
STEVA, STDEVPA STDEV.S, VAR.P, VAR.S
Probability Functions:
COMBIN, FACT, PERMUT, PROB
Binomial Distribution Functions:
BINOM.DIST, BINOMI.INV

Exponential Distribution Functions:
EXPON.DIST
Hypergeometric Distribution Functions:
HYPOGEOM.DIST
Poisson Distribution Functions:
POISSON.DIST,
Normal Distribution Functions:
NORMAL.DIST, NORM.INV, NORM.S.INV, NORM.SINV, STANDARDIZE
t Distribution Functions:
T.DIST, T.DIST.2T, T.DIST.RT, T.INV, T.INV.2T, and T.TEST
Confidence Interval Functions:
CONFIDENCE.NORM and CONFIDENCE.T
F Distribution Functions:
FDIST, FDISTRT, FINV, FINVRT
Chi-Square Functions:
CHISQ.DIST, CHISQ.DISTRT, CHISQ-INV, and CHISQ-INVRT
Exponential Distribution Functions:
EXPON.DIST
Correlation and Regression Functions:
CORREL, DEVEQ, INTERCEPT, LINEST, PEARSON, RSQ, SLOP, STEYX, TREND
Q. Greek Letters Commonly Used in Statistics
Greek
Letter
Upper
Case
Lower
Case
Statistical Symbol
Alpha
Α
α
α = level of significance, Type I Error

Beta
Β
β
β = Type II Error; 1 – β = Power of the test
Gamma
Γ
γ
Delta
Δ
δ
Epsilon
Ε
ε
Zeta
Ζ
ζ
Eta
Η
η
Theta
Θ
θ
Iota
Ι
ι
Kappa
Κ
κ
Lambda
Λ
λ
Mu
Μ
μ
μ = population mean
Nu
Ν
ν
ν = degrees of freedom (df)
Xi
Ξ
ξ
Omicron
Ο
ο
Pi
Π
π
π = population proportion
Rho
Ρ
ρ
ρ = linear correlation of a population
Sigma
Σ
σ
Σ = “Sum of” or summation; σ
2
= population variance;
σ = population standard deviation
Tau
Τ
τ
Upsilon
Υ
υ
Phi
Φ
φ
Chi
Χ
χ
Chi Square statistics (χ
2
)
Psi
Ψ
ψ
Omega
Ω
ω

